I'm the founder and CEO of INCAR Robotics AB, a robotics startup focusing on teleoperation, telepresence, and skill learning. Before starting INCAR Robotics, I was a Postdoctoral Researcher working with Danica Kragic, at the Robotics, Perception and Learning Lab (RPL), EECS, at KTH in Stockholm, Sweden. Where I also did my PhD under Danica Kragics supervission as well as co-supervision of Anastasiia Varava, and Hang Yin.
I'm working on learning representations for rigid and deformable objects manipulation. My work includes partial caging as well as working with highly deformable objects (clothing).
My CV can be found here (not neccesary up to date).
Recent Work
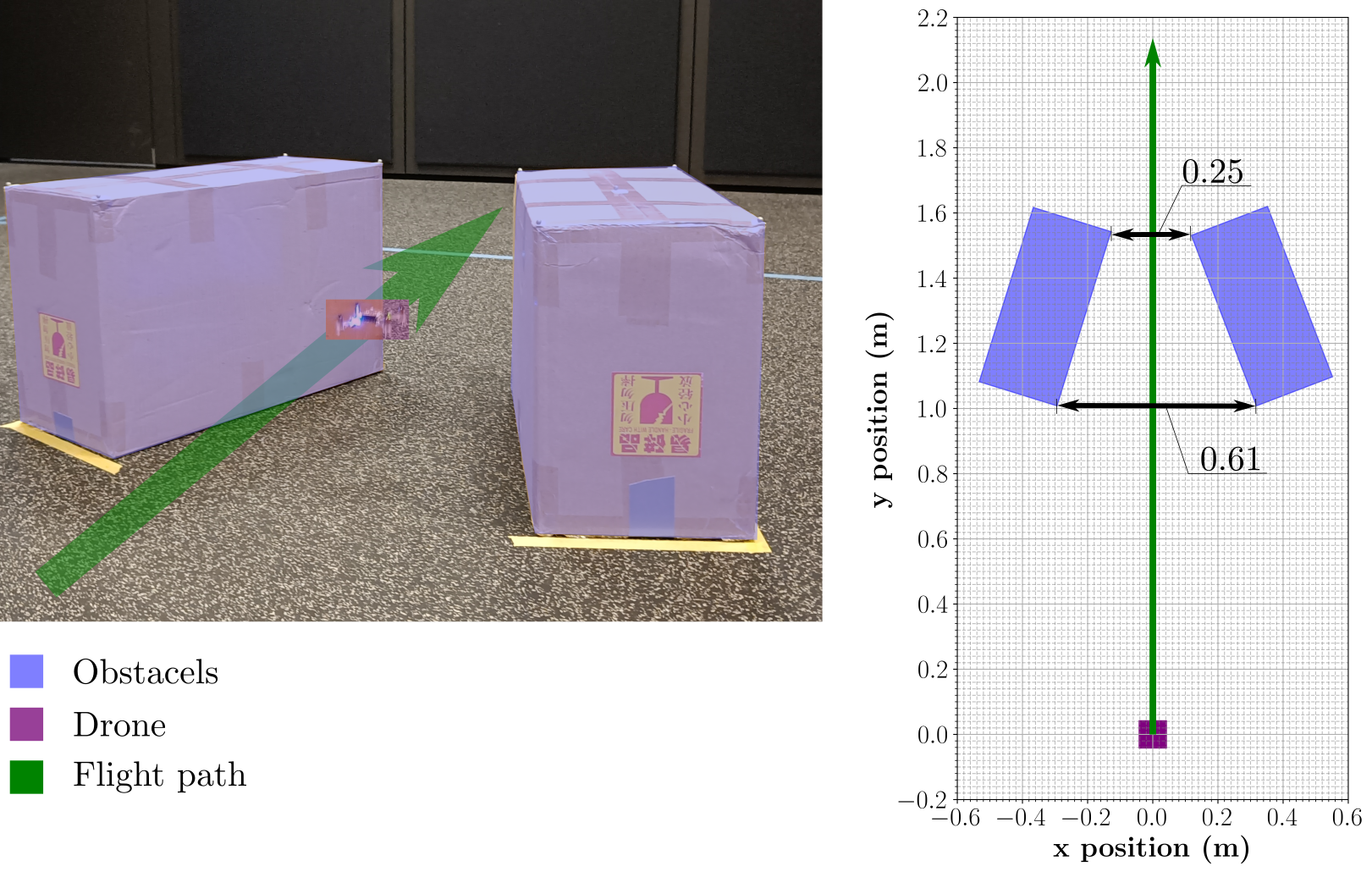
Towards Safe Reinforcement Learning with Reduced Conservativeness: A Case Study on Drone Flight Control
Loizos Hadjiloizou, Michael C. Welle, Hang Yin, Danica Kragic
Abstract—
Incorporating formal methods into reinforcement learning (RL) has the potential to result in the best of both worlds, combining the robustness of formal guarantees with the adaptability and learning capabilities of RL, though careful design is needed to balance safety and exploration.
In his work, we propose a framework to mitigate this loss of exploration while still allowing for the safety of the system to be ensured. Specifically, we introduce a less restrictive method that can reduce the conservativeness of formal methods by refining a disturbance model using online collected data and it evaluates the safety of a learning-based controller, using computationally efficient zonotopic reachability analysis for the safety analysis to facilitate a real-time implementation. We validate the framework in a real-world drone flight through a canyon, where the drone is subjected to unknown external disturbances and the framework is tasked with learning those disturbances online and adjusting the safety guarantees accordingly. The results show that the framework enables a less restrictive online training of learning-based controllers without compromising the safety of the system.
Submitted to ICRA 2024
Publications
Journal Papers:
Transfer learning in robotics: An upcoming breakthrough? A review of promises and challenges
Transfer learning is a conceptually-enticing paradigm in pursuit of truly intelligent embodied agents. The core concept—reusing prior knowledge to learn in and from novel situations—is successfully leveraged by humans to handle novel situations. In recent years, transfer learning has received renewed interest from the community from different perspectives, including imitation learning, domain adaptation, and transfer of experience from simulation to the real world, among others. In this paper, we unify the concept of transfer learning in robotics and provide the first taxonomy of its kind considering the key concepts of robot, task, and environment. Through a review of the promises and challenges in the field, we identify the need of transferring at different abstraction levels, the need of quantifying the transfer gap and the quality of transfer, as well as the dangers of negative transfer. Via this position paper, we hope to channel the effort of the community towards the most significant roadblocks to realize the full potential of transfer learning in robotics.
Transfer learning in robotics: An upcoming breakthrough? A review of promises and challenges
Noémie Jaquier*, Michael C. Welle*, Andrej Gams, Kunpeng Yao, Bernardo Fichera, Aude Billard, Aleš Ude, Tamim Asfour, Danica Kragic
Published in The International Journal of Robotics Research, 2024
Unfolding the Literature: A Review of Robotic Cloth Manipulation
The realm of textiles spans clothing, households, healthcare, sports, and industrial applications. The deformable nature of these objects poses unique challenges that prior work on rigid objects cannot fully address. The increasing interest within the community in textile perception and manipulation has led to new methods that aim to address challenges in modeling, perception, and control, resulting in significant progress. However, this progress is often tailored to one specific textile or a subcategory of these textiles. To understand what restricts these methods and hinders current approaches from generalizing to a broader range of real-world textiles, this review provides an overview of the field, focusing specifically on how and to what extent textile variations are addressed in modeling, perception, benchmarking, and manipulation of textiles. We conclude by identifying key open problems and outlining grand challenges that will drive future advancements in the field.
Unfolding the Literature: A Review of Robotic Cloth Manipulation
Alberta Longhini, Yufei Wang, Irene Garcia-Camacho, David Blanco-Mulero, Marco Moletta, Michael Welle, Guillem Alenyà, Hang Yin, Zackory Erickson, David Held, Júlia Borràs, Danica Kragic
Published in Annual Review of Control, Robotics, and Autonomous Systems, 2024
AdaFold: Adapting Folding Trajectories of Cloths via Feedback-Loop Manipulation
We present AdaFold, a model-based feedback-loop framework for optimizing folding trajectories. AdaFold extracts a particle-based representation of cloth from RGB-D images and feeds back the representation to a model predictive control to re-plan folding trajectory at every time-step. A key component of AdaFold that enables feedback-loop manipulation is the use of semantic descriptors extracted from geometric features. These descriptors enhance the particle representation of the cloth to distinguish between ambiguous point clouds of differently folded cloths. Our experiments demonstrate AdaFold's ability to adapt folding trajectories of cloths with varying physical properties and generalize from simulated training to real-world execution.
Enabling Visual Action Planning for Object Manipulation through Latent Space Roadmap
We present a framework for visual action planning of complex manipulation tasks with high-dimensional state spaces, focusing on manipulation of deformable objects. We propose a Latent Space Roadmap (LSR) for task planning which is a graph-based structure globally capturing the system dynamics in a low-dimensional latent space.
Our framework consists of three parts: (1) a Mapping Module (MM) that maps observations given in the form of images into a structured latent space extracting the respective states as well as generates observations from the latent states, (2) the LSR which builds and connects clusters containing similar states in order to
find the latent plans between start and goal states extracted by MM, and (3) the Action Proposal Module that complements the latent plan found by the LSR with the corresponding actions. We present a thorough investigation of our framework on simulated box stacking and rope/box manipulation tasks, and a folding task executed on a real robot.
Enabling Visual Action Planning for Object Manipulation through Latent Space Roadmap
Martina Lippi*, Petra Poklukar*, Michael C. Welle*, Anastasia Varava, Hang Yin, Alessandro Marino, and Danica Kragic
Puplished in Transactions on Robotics (TRO), 2022
Partial Caging: A Clearance-Based Definition, Datasets and Deep Learning
Caging grasps limit the mobility of an ob-
ject to a bounded component of configuration space.
We introduce a notion of partial cage quality based
on maximal clearance of an escaping path. As comput-
ing this is a computationally demanding task even in
a two-dimensional scenario, we propose a deep learn-
ing approach. We design two convolutional neural net-
works and construct a pipeline for real-time planar par-
tial cage quality estimation directly from 2D images
of object models and planar caging tools. One neural
network, CageMaskNN, is used to identify caging tool
locations that can support partial cages, while a sec-
ond network that we call CageClearanceNN is trained
to predict the quality of those configurations. A partial
caging dataset of 3811 images of objects and more than
19 million caging tool configurations is used to train
and evaluate these networks on previously unseen ob-
jects and caging tool configurations. Experiments show
that evaluation of a given configuration on a GeForce
GTX 1080 GPU takes less than 6 ms. Furthermore, an
additional dataset focused on grasp-relevant configura-
tions is curated and consists of 772 objects with 3.7
million configurations. We also use this dataset for 2D
Cage acquisition on novel objects. We study how net-
work performance depends on the datasets, as well as
how to efficiently deal with unevenly distributed training data. In further analysis, we show that the evalua-
tion pipeline can approximately identify connected re-
gions of successful caging tool placements and we eval-
uate the continuity of the cage quality score evaluation
along caging tool trajectories. Influence of disturbances
is investigated and quantitative results are provided.
Partial Caging: A Clearance-Based Definition, Datasets and Deep Learning
Michael Welle, Anastasiia Varava, Jeffrey Mahler, Ken Goldberg, Danica Kragic, and Florian T. Pokorny
Published in Autonomous Robots, Special Issue Topological Methods in Robotics 2021
Cloth manipulation is a challenging task that, despite its importance, has received relatively little attention compared to rigid object manipulation. In this letter, we provide three benchmarks for evaluation and comparison of different approaches towards three basic tasks in cloth manipulation: spreading a tablecloth over a table, folding a towel, and dressing. The tasks can be executed on any bimanual robotic platform and the objects involved in the tasks are standardized and easy to acquire. We provide several complexity levels for each task, and describe the quality measures to evaluate task execution. Furthermore, we provide baseline solutions for all the tasks and evaluate them according to the proposed metrics.
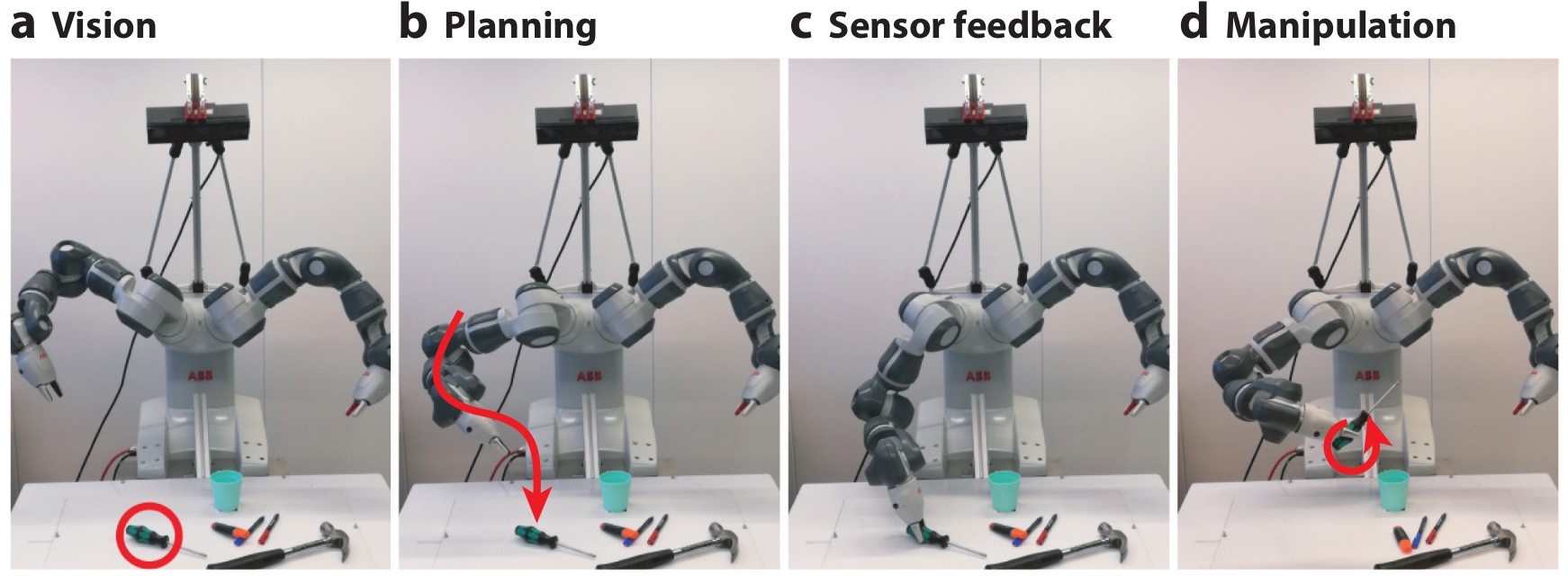
From Visual Understanding to Complex Object Manipulation
Planning and executing object manipulation requires integrating multiple
sensory and motor channels while acting under uncertainty and complying
with task constraints. As the modern environment is tuned for human hands,
designing robotic systems with similar manipulative capabilities is crucial.
Research on robotic object manipulation is divided into smaller communities
interested in, e.g., motion planning, grasp planning, sensorimotor learning,
and tool use. However, few attempts have been made to combine these areas
into holistic systems. In this review, we aim to unify the underlying mechanics
of grasping and in-hand manipulation by focusing on the temporal aspects of
manipulation, including visual perception, grasp planning and execution, and
goal-directed manipulation. Inspired by human manipulation, we envision
that an emphasis on the temporal integration of these processes opens the
way for human-like object use by robots.
From Visual Understanding to Complex Object Manipulation
Judith Butepage, Silvia Cruciani, Mia Kokic, Michael Welle, and Danica Kragic
Published in Annual Review of Control, Robotics, and Autonomous Systems (2019)
Puppeteer Your Robot: Augmented Reality Leader-Follower Teleoperation
High-quality demonstrations are necessary when learning complex and challenging manipulation tasks. In this work, we introduce an approach to puppeteer a robot by controlling a virtual robot in an augmented reality setting. Our system allows for retaining the advantages of being intuitive from a physical leader-follower side while avoiding the unnecessary use of expensive physical setup. In addition, the user is endowed with additional information using augmented reality. We validate our system with a pilot study n = 10 on a block stacking and rice scooping tasks where the majority rates the system favorably. Oculus App and corresponding ROS code are available on the project website
Puppeteer Your Robot: Augmented Reality Leader-Follower Teleoperation
Jonne Van Haastregt*, Michael C. Welle*, Yuchong Zhang, Danica Kragic
Puplished in IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids), 2024
Low-Cost Teleoperation with Haptic Feedback through Vision-based Tactile Sensors for Rigid and Soft Object Manipulation
Haptic feedback is essential for humans to successfully perform complex and delicate manipulation tasks. A recent rise in tactile sensors has enabled robots to leverage the sense of touch and expand their capability drastically. However, many tasks still need human intervention/guidance. For this reason, we present a teleoperation framework designed to provide haptic feedback to human operators based on the data from camera-based tactile sensors mounted on the robot gripper. Partial autonomy is introduced to prevent slippage of grasped objects during task execution. Notably, we rely exclusively on low-cost off-the-shelf hardware to realize an affordable solution. We demonstrate the versatility of the framework on nine different objects ranging from rigid to soft and fragile ones, using three different operators on real hardware.
Low-Cost Teleoperation with Haptic Feedback through Vision-based Tactile Sensors for Rigid and Soft Object Manipulation
Martina Lippi*; Michael C. Welle*; Maciej K. Wozniak; Andrea Gasparri; Danica Kragic
Puplished in 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN), 2024
Visual Action Planning with Multiple Heterogeneous Agents
Visual planning methods are promising to handle complex settings where extracting the system state is challenging. However, none of the existing works tackles the case of multiple heterogeneous agents which are characterized by different capabilities and/or embodiment. In this work, we propose a method to realize visual action planning in multi-agent settings by exploiting a roadmap built in a low-dimensional structured latent space and used for planning. To enable multi-agent settings, we infer possible parallel actions from a dataset composed of tuples associated with individual actions. Next, we evaluate feasibility and cost of them based on the capabilities of the multi-agent system and endow the roadmap with this information, building a capability latent space roadmap (C-LSR). Additionally, a capability suggestion strategy is designed to inform the human operator about possible missing capabilities when no paths are found. The approach is validated in a simulated burger cooking task and a real-world box packing task.
Visual Action Planning with Multiple Heterogeneous Agents
Martina Lippi*; Michael C. Welle*; Marco Moletta; Alessandro Marino; Andrea Gasparri; Danica Kragic
Puplished in 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN), 2024
A Robotic Skill Learning System Built Upon Diffusion Policies and Foundation Models
In this paper, we build upon two major recent developments in the field, Diffusion Policies for visuomotor manipulation and large pre-trained multimodal foundational models to obtain a robotic skill learning system. The system can obtain new skills via the behavioral cloning approach of visuomotor diffusion policies given teleoperated demonstrations. Foundational models are being used to perform skill selection given the user’s prompt in natural language. Before executing a skill the foundational model performs a precondition check given an observation of the workspace. We compare the performance of different foundational models to this end and give a detailed experimental evaluation of the skills taught by the user in simulation and the real world. Finally, we showcase the combined system on a challenging food serving scenario in the real world. Videos of all experimental executions, as well as the process of teaching new skills in simulation and the real world, are available on the project’s website
A Robotic Skill Learning System Built Upon Diffusion Policies and Foundation Models
Nils Ingelhag*; Jesper Munkeby*; Jonne van Haastregt*; Anastasia Varava; Michael C. Welle; Danica Kragic
Puplished in 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN), 2024
Ensemble Latent Space Roadmap for Improved Robustness in Visual Action Planning
Planning in learned latent spaces helps to decrease the dimensionality of raw observations. In this work, we propose to leverage the ensemble paradigm to enhance the robustness of latent planning systems. We rely on our Latent Space Roadmap (LSR) framework, which builds a graph in a learned structured latent space to perform planning. Given multiple LSR framework instances, that differ either on their latent spaces or on the parameters for constructing the graph, we use the action information as well as the embedded nodes of the produced plans to define similarity measures. These are then utilized to select the most promising plans. We validate the performance of our Ensemble LSR (ENS-LSR) on simulated box stacking and grape harvesting tasks as well as on a real-world robotic T-shirt folding experiment.
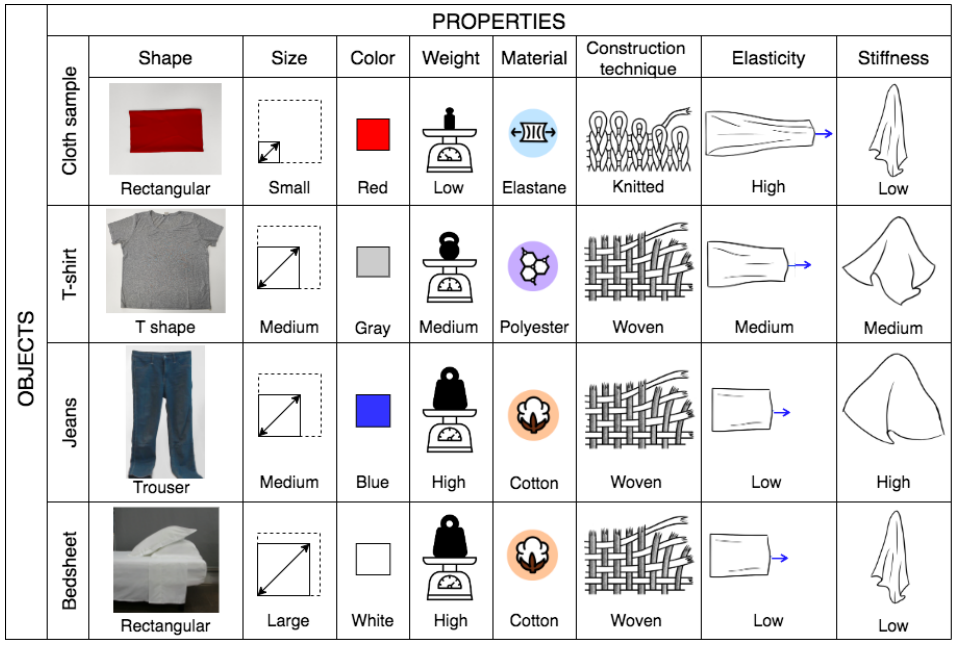
Standardization of Cloth Objects and its Relevance in Robotic Manipulation
The field of robotics faces inherent challenges in manipulating deformable objects, particularly in understanding and standardising fabric properties like elasticity, stiffness, and friction. While the significance of these properties is evident in the realm of cloth manipulation, accurately categorising and comprehending them in real-world applications remains elusive. This study sets out to address two primary objectives: (1) to provide a framework suitable for robotics applications to characterise cloth objects, and (2) to study how these properties influence robotic manipulation tasks. Our preliminary results validate the framework’s ability to characterise cloth properties and compare cloth sets, and reveal the influence that different properties have on the outcome of five manipulation primitives. We believe that, in general, results on the manipulation of clothes should be reported along with a better description of the garments used in the evaluation. This paper proposes a set of these measures.
Standardization of Cloth Objects and its Relevance in Robotic Manipulation
Irene Garcia-Camacho; Alberta Longhini; Michael Welle; Guillem Alenyà; Danica Kragic; Júlia Borràs
Puplished in IEEE International Conference on Robotics and Automation (ICRA), 2024
A Virtual Reality Framework for Human-Robot Collaboration in Cloth Folding
Endowing robots with tactile capabilities opens up new possibilities for their interaction with the environment, including the ability to handle fragile and/or soft objects. In this work, we equip the robot gripper with low-cost vision-based tactile sensors and propose a manipulation algorithm that adapts to both rigid and soft objects without requiring any knowledge of their properties. The algorithm relies on a touch and slip detection method, which considers the variation in the tactile images with respect to reference ones. We validate the approach on seven different objects, with different properties in terms of rigidity and fragility, to perform unplugging and lifting tasks. Furthermore, to enhance applicability, we combine the manipulation algorithm with a grasp sampler for the task of finding and picking a grape from a bunch without damaging it.
A Virtual Reality Framework for Human-Robot Collaboration in Cloth Folding
Marco Moletta; Maciej K. Wozniak; Michael C. Welle; Danica Kragic
Puplished in IEEE-RAS 22nd International Conference on Humanoid Robots (Humanoids) (CASE), 2023
Enabling Robot Manipulation of Soft and Rigid Objects with Vision-based Tactile Sensors
Endowing robots with tactile capabilities opens up new possibilities for their interaction with the environment, including the ability to handle fragile and/or soft objects. In this work, we equip the robot gripper with low-cost vision-based tactile sensors and propose a manipulation algorithm that adapts to both rigid and soft objects without requiring any knowledge of their properties. The algorithm relies on a touch and slip detection method, which considers the variation in the tactile images with respect to reference ones. We validate the approach on seven different objects, with different properties in terms of rigidity and fragility, to perform unplugging and lifting tasks. Furthermore, to enhance applicability, we combine the manipulation algorithm with a grasp sampler for the task of finding and picking a grape from a bunch without damaging it.
Enabling Robot Manipulation of Soft and Rigid Objects with Vision-based Tactile Sensors
Michael C. Welle; Martina Lippi; Haofei Lu; Jens Lundell; Andrea Gasparri; Danica Kragic
Puplished in IEEE 19th International Conference on Automation Science and Engineering (CASE), 2023
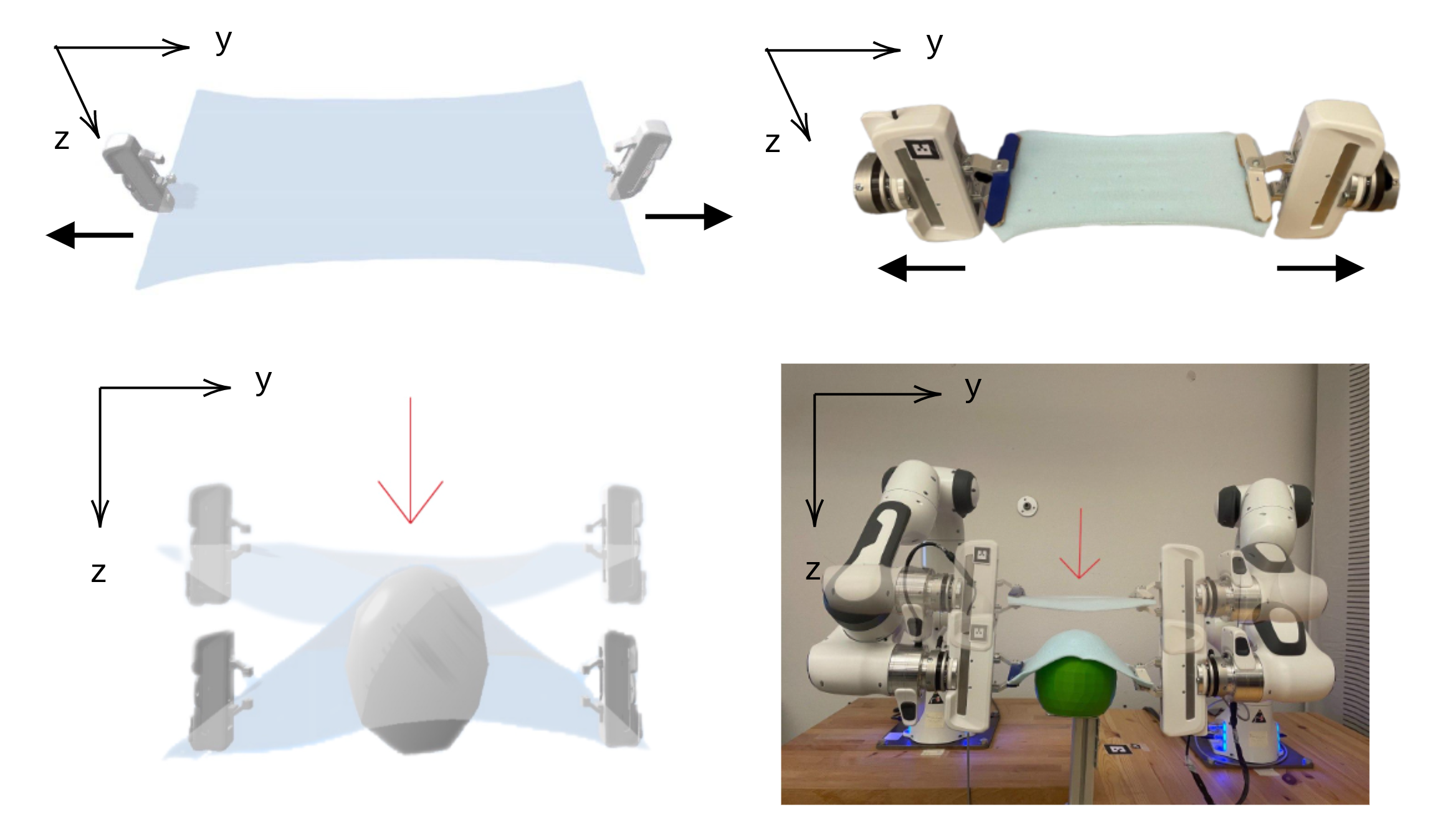
EDO-Net: Learning Elastic Properties of Deformable Objects from Graph Dynamics
We study the problem of learning graph dynamics of deformable objects that generalizes to unknown physical properties. Our key insight is to leverage a latent representation of elastic physical properties of cloth-like deformable objects that can be extracted, for example, from a pulling interaction.
In this paper we propose EDO-Net (Elastic Deformable Object - Net), a model of graph dynamics trained on a large variety of samples with different elastic properties that does not rely on ground-truth labels of the properties. EDO-Net jointly learns an adaptation module, and a forward-dynamics module. The former is responsible for extracting a latent representation of the physical properties of the object, while the latter leverages the latent representation to predict future states of cloth-like objects represented as graphs. We evaluate EDO-Net both in simulation and real world, assessing its capabilities of: 1) generalizing to unknown}physical properties, 2) transferring the learned representation to new downstream tasks.
EDO-Net: Learning Elastic Properties of Deformable Objects from Graph Dynamics
Alberta Longhini, Marco Moletta, Alfredo Reichlin, Michael C Welle, David Held, Zackory Erickson, Danica Kragic
Puplished in International Conference on Robotics and Automation (ICRA), 2023
Elastic Context: Encoding Elasticity for Data-driven Models of Textiles
Physical interaction with textiles, such as assistive dressing or household tasks, requires advanced dexterous skills. The complexity of textile behavior during stretching and pulling is influenced by the material properties of the yarn and by the textile's construction technique, which are often unknown in real-world settings. Moreover, identification of physical properties of textiles through sensing commonly available on robotic platforms remains an open problem. To address this, we introduce Elastic Context (EC), a method to encode the elasticity of textiles using stress-strain curves adapted from textile engineering for robotic applications. We employ EC to learn generalized elastic behaviors of textiles and examine the effect of EC dimension on accurate force modeling of real-world non-linear elastic behaviors.
Elastic Context: Encoding Elasticity for Data-driven Models of Textiles
Alberta Longhini, Marco Moletta, Alfredo Reichlin, Michael C Welle, Alexander Kravberg, Yufei Wang, David Held, Zackory Erickson, Danica Kragic
Puplished inInternational Conference on Robotics and Automation (ICRA), 2023
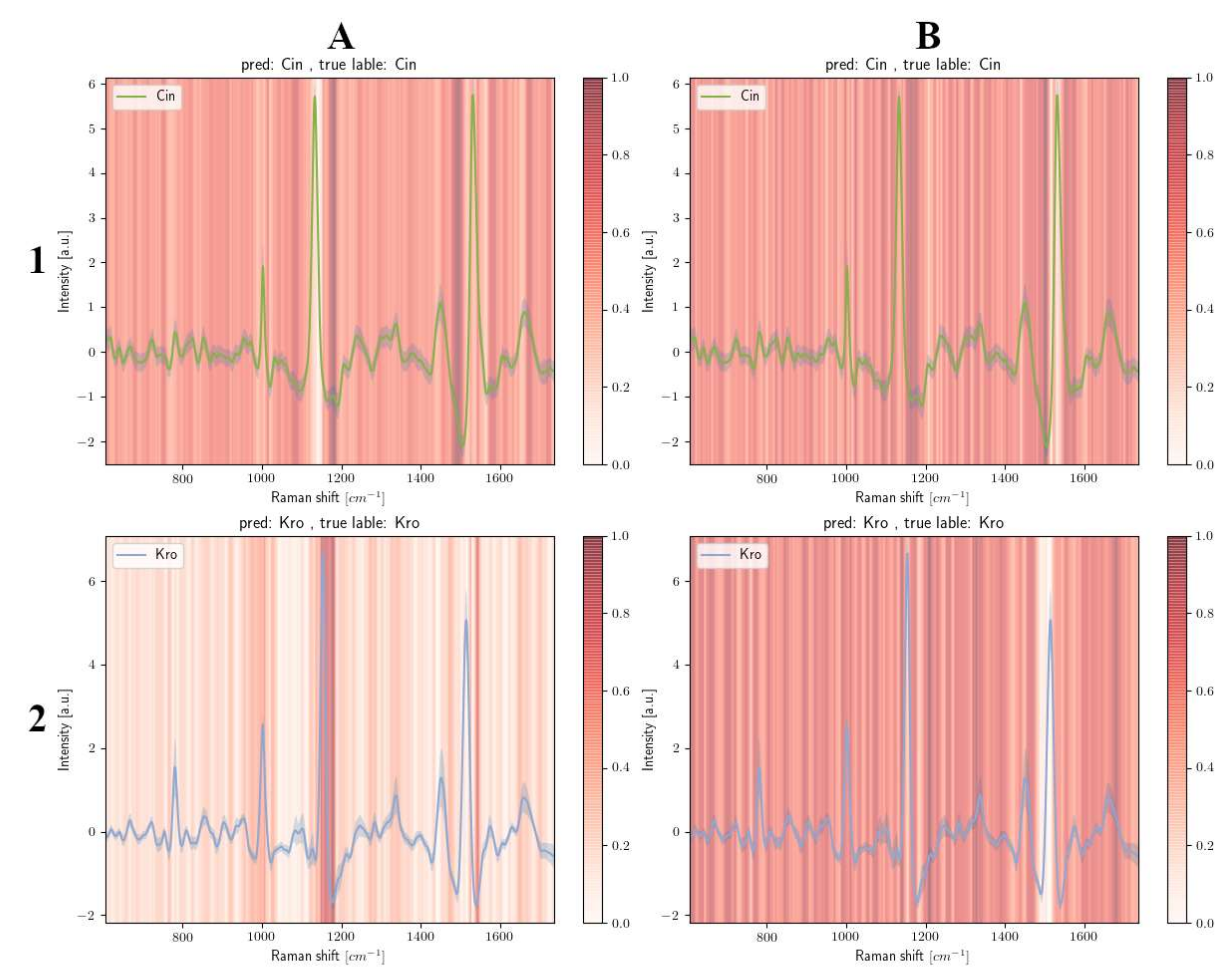
Understanding Raman Spectral Based Classifications with Convolutional Neural Networks Using Practical Examples of Fungal Spores and Carotenoid-Pigmented Microorganisms
Physical interaction with textiles, such as assistive dressing or household tasks, requires advanced dexterous skills. The complexity of textile behavior during stretching and pulling is influenced by the material properties of the yarn and by the textile's construction technique, which are often unknown in real-world settings. Moreover, identification of physical properties of textiles through sensing commonly available on robotic platforms remains an open problem. To address this, we introduce Elastic Context (EC), a method to encode the elasticity of textiles using stress-strain curves adapted from textile engineering for robotic applications. We employ EC to learn generalized elastic behaviors of textiles and examine the effect of EC dimension on accurate force modeling of real-world non-linear elastic behaviors.
Understanding Raman Spectral Based Classifications with Convolutional Neural Networks Using Practical Examples of Fungal Spores and Carotenoid-Pigmented Microorganisms
Thomas J. Tewes, Michael C. Welle, Bernd T. Hetjens, Kevin Saruni Tipatet, Svyatoslav Pavlov, Frank Platte, Dirk P. Bockmühl
Puplished in AI, 2023
Augment-Connect-Explore: a Paradigm for Visual Action Planning with Data Scarcity
Visual action planning particularly excels in applications where the state of the system cannot be computed explicitly, such as manipulation of deformable objects, as it enables planning directly from raw images.
Even though the field has been significantly accelerated by deep learning techniques, a crucial requirement for their success is the availability of a large amount of data.
In this work, we propose the Augment-Connect-Explore (ACE) paradigm to enable visual action planning in cases of data scarcity.
We build upon the Latent Space Roadmap (LSR) framework which performs planning with a graph built in a low dimensional latent space. In particular, ACE is used to i) Augment the available training dataset by autonomously creating new pairs of datapoints, ii) create new unobserved Connections among representations of states in the latent graph, and iii) Explore new regions of the latent space in a targeted manner. We validate the proposed approach on both simulated box stacking and real-world folding task showing the applicability for rigid and deformable object manipulation tasks, respectively.
Augment-Connect-Explore: a Paradigm for Visual Action Planning with Data Scarcity
Martina Lippi*, Michael C. Welle*, Petra Poklukar, Alessandro Marino and Danica Kragic
Puplished in International Conference on Intelligent Robots and Systems (IROS2022)
Embedding Koopman Optimal Control in Robot Policy Learning
Embedding an optimization process has been explored for imposing efficient and flexible policy structures. Existing work often build upon nonlinear optimization with explicitly iteration steps, making policy inference prohibitively expensive for online learning and real-time control. Our approach embeds a linear-quadratic-regulator (LQR) formulation with a Koopman representation, thus exhibiting the tractability from a closed-form solution and richness from a non-convex neural network. We use a few auxiliary objectives and reparameterization to enforce optimality conditions of the policy that can be easily integrated to standard gradient-based learning. Our approach is shown to be effective for learning policies rendering an optimality structure and efficient reinforcement learning, including simulated pendulum control, 2D and 3D walking, and manipulation for both rigid and deformable objects. We also demonstrate real world application in a robot pivoting task.
Comparing Reconstruction- and Contrastive-based Models for Visual Task Planning
Learning state representations enables robotic planning directly from raw observations such as images.
Most methods learn state representations by utilizing losses based on the reconstruction of the raw observations from a lower-dimensional latent space.
The similarity between observations in the space of images is often assumed and used as a proxy for estimating similarity between the underlying
states of the system.
However, observations commonly contain task-irrelevant factors of variation which are nonetheless important for reconstruction, such as varying lighting and different camera viewpoints.
In this work, we define relevant evaluation metrics and perform a thorough study of different loss functions for state representation learning.
We show that models exploiting task priors, such as Siamese networks with a simple contrastive loss, outperform
Comparing Reconstruction- and Contrastive-based Models for Visual Task Planning
Constantinos Chamzas*, Martina Lippi*, Michael C. Welle*, Anastasia Varava, Lydia E. Kavraki, and Danica Kragic
Puplished in International Conference on Intelligent Robots and Systems (IROS2022)
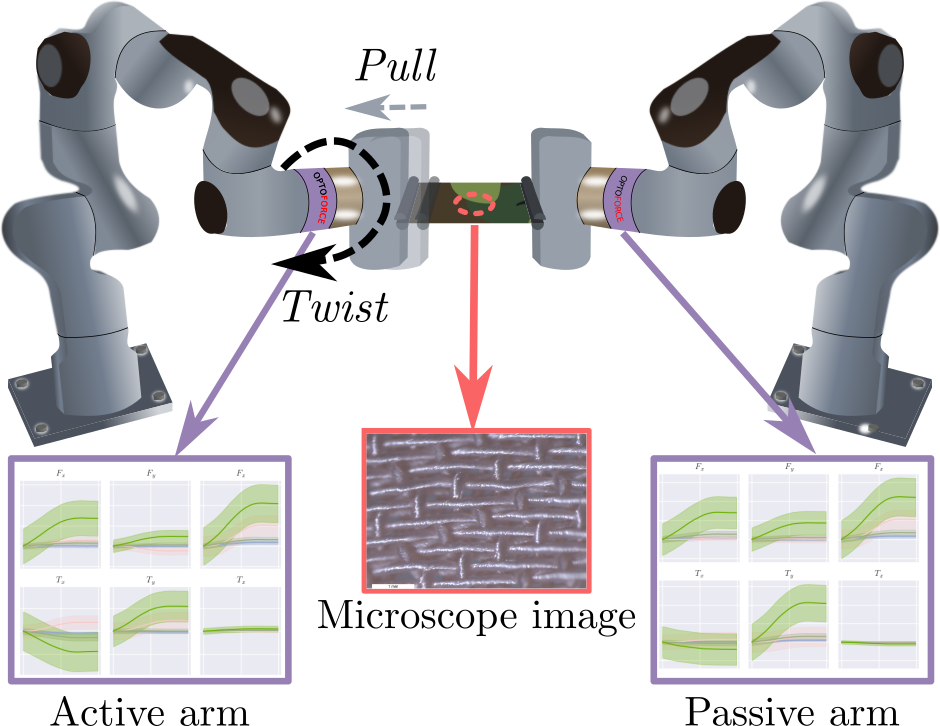
Textile Taxonomy and Classification Using Pulling and Twisting
Identification of textile properties is an important milestone toward advanced robotic manipulation tasks that consider interaction with clothing items such as assisted dressing, laundry folding, automated sewing, textile recycling and reusing. Despite the abundance of work considering this class of deformable objects, many open problems remain. These relate to the choice and modelling of the sensory feedback as well as the control and planning of the interaction and manipulation strategies. Most importantly, there is no structured approach for studying and assessing different approaches that may bridge the gap between the robotics community and textile production industry. To this end, we outline a textile taxonomy considering fiber types and production methods, commonly used in textile industry. We devise datasets according to the taxonomy, and study how robotic actions, such as pulling and twisting of the textile samples, can be used for the classification. We also provide important insights from the perspective of visualization and interpretability of the gathered data.
Textile Taxonomy and Classification Using Pulling and Twisting
Alberta Longhini, Michael C. Welle, Ioanna Mitsioni and Danica Kragic
Accepted in International Conference on Intelligent Robots and Systems (IROS2021)
Learning Task Constraints in Visual-Action Planning from Demonstrations
Visual planning approaches have shown great success for decision making tasks with no explicit model of the state space. Learning a suitable representation and constructing a latent space where planning can be performed allows non-experts to setup and plan motions by just providing images.
However, learned latent spaces are usually not semantically-interpretable, and thus it is difficult to integrate task constraints. We propose a novel framework to determine whether plans satisfy constraints given demonstrations of policies that satisfy or violate the constraints.
The demonstrations are realizations of Linear Temporal Logic formulas which are employed to train Long Short-Term Memory (LSTM) networks directly in the latent space representation.
We demonstrate that our architecture enables designers to easily specify, compose and integrate task constraints and achieves high performance in terms of accuracy. Furthermore, this visual planning framework enables human interaction, coping the environment changes that a human worker may involve.
We show the flexibility of the method on a box pushing task in a simulated warehouse setting with different task constraints.
Learning Task Constraints in Visual-Action Planning from Demonstrations
Francesco Esposito, Christian Pek, Michael C. Welle and Danica Kragic
Puplished in IEEE Int. Conf. on Robot and Human Interactive Communication (ROMAN2021)
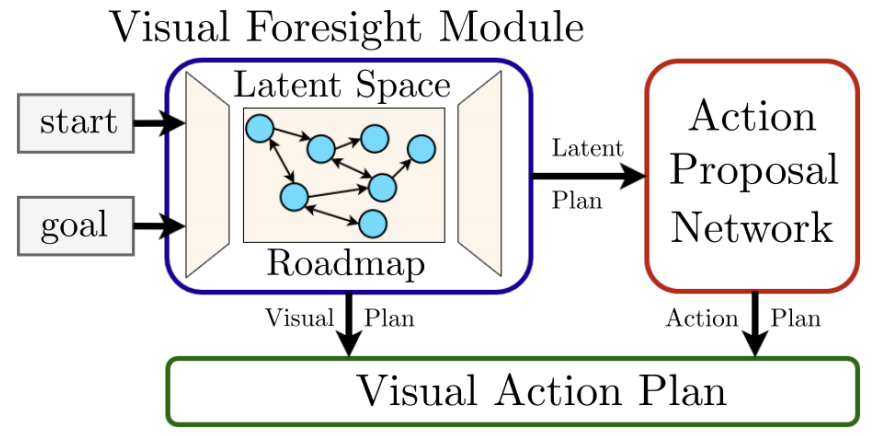
Latent Space Roadmap for Visual Action Planning of Deformable and Rigid Object Manipulation
We present a framework for visual action planning
of complex manipulation tasks with high-dimensional state
spaces such as manipulation of deformable objects. Planning is
performed in a low-dimensional latent state space that embeds
images. We define and implement a Latent Space Roadmap
(LSR) which is a graph-based structure that globally captures
the latent system dynamics. Our framework consists of two
main components: a Visual Foresight Module (VFM) that
generates a visual plan as a sequence of images, and an Action
Proposal Network (APN) that predicts the actions between
them. We show the effectiveness of the method on a simulated
box stacking task as well as a T-shirt folding task performed
with a real robot.
Latent Space Roadmap for Visual Action Planning of Deformable and Rigid Object Manipulation
Martina Lippi*, Petra Poklukar*, Michael C. Welle*, Anastasiia Varava, Hang Yin, Alessandro Marino, and Danica Kragic
Puplished in International Conference on Intelligent Robots and Systems (IROS2020)
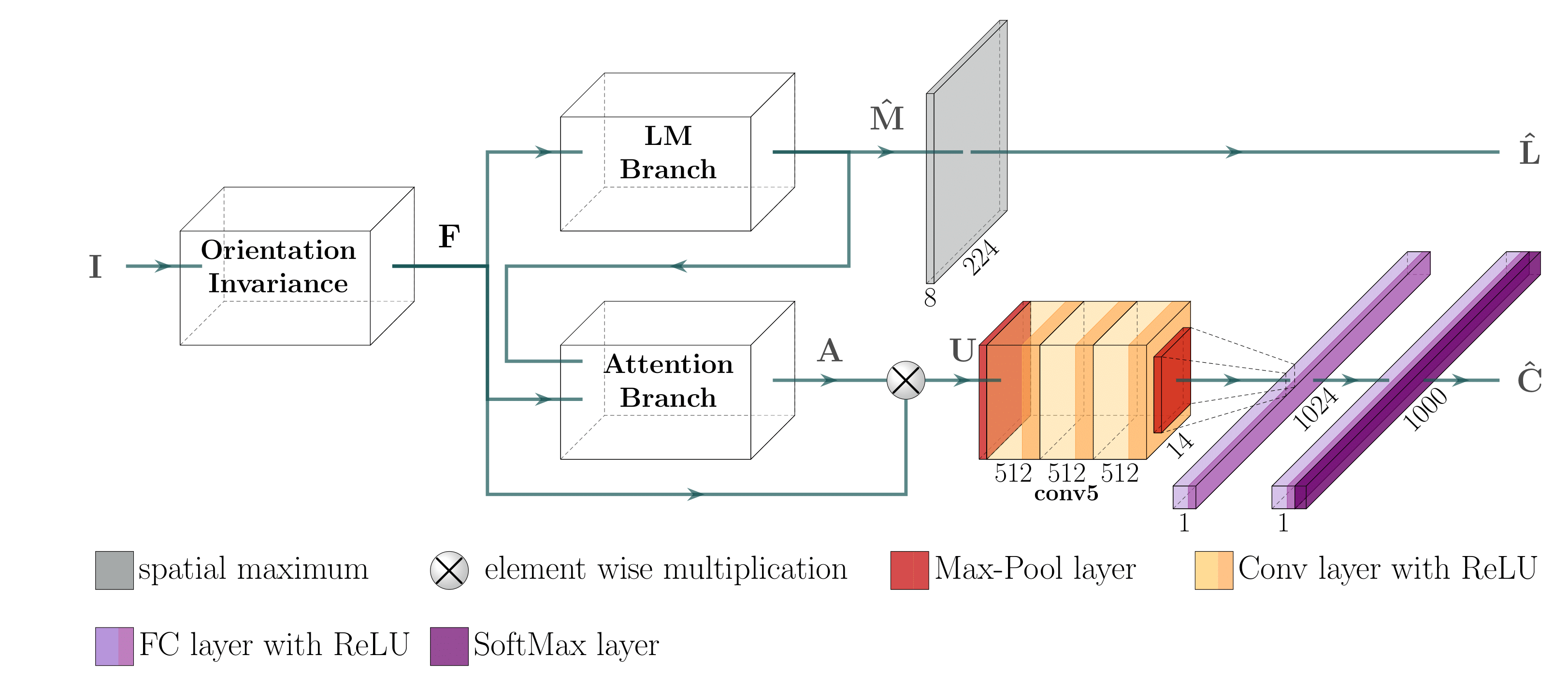
Fashion Landmark Detection and Category Classification for Robotics
Research on automatic identification of clothing
categories and fashion landmarks based on images has recently
gained significant interest in the research community due to its
potential impact on various areas such as robotic clothing ma-
nipulation, automated clothes sorting and recycling, and online
shopping, to name a few. Several public large annotated fashion
datasets have been created recently to facilitate research advances
in this direction. In this work, we make the first step towards
leveraging the data and techniques developed for fashion image
analysis in vision-based robotic clothing manipulation tasks. We
focus on techniques that can generalize from large-scale fashion
datasets to less structured, small datasets collected in a robotic
lab. Specifically, we propose training data augmentation methods
such as elastic warping, and model adjustments such as rotation
invariant convolutions to make the model generalize better. Our
experiments demonstrate that our approach outperforms state-
of-the art models with respect to clothing category classification
and fashion landmark detection when tested on previously unseen
datasets. Furthermore, we present experimental results on a
new small dataset composed of images on which a robot holds
different garments, collected in our lab.
Fashion Landmark Detection and Category Classification for Robotics
Thomas Ziegler, Judith Butepage, Michael C. Welle, Anastasiia Varava, Tonci Novkovic and Danica Kragic
Published in IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC2020)
Partial Caging: A Clearance-Based Definition and Deep Learning
Caging grasps limit the mobility of an object to
a bounded component of configuration space. We introduce a
notion of partial cage quality based on maximal clearance of
an escaping path. As this is a computationally demanding task
even in a two-dimensional scenario, we propose a deep learning
approach. We design two convolutional neural networks and
construct a pipeline for real-time partial cage quality estimation
directly from 2D images of object models and planar caging
tools. One neural network, CageMaskNN, is used to identify
caging tool locations that can support partial cages, while
a second network that we call CageClearanceNN is trained
to predict the quality of those configurations. A dataset of
3811 images of objects and more than 19 million caging tool
configurations is used to train and evaluate these networks
on previously unseen objects and caging tool configurations.
Furthermore, the networks are trained jointly on configurations
for both 3 and 4 caging tool configurations whose shape
varies along a 1-parameter family of increasing elongation. In
experiments, we study how the networks’ performance depends
on the size of the training dataset, as well as how to efficiently
deal with unevenly distributed training data. In further analysis,
we show that the evaluation pipeline can approximately identify
connected regions of successful caging tool placements and we
evaluate the continuity of the cage quality score evaluation along
caging tool trajectories. Experiments show that evaluation of
a given configuration on a GeForce GTX 1080 GPU takes less
than 6 ms.
Partial Caging: A Clearance-Based Definition and Deep Learning
Anastasiia Varava*, Michael Welle*, Jeffrey Mahler, Ken Goldberg, Danica Kragic, and Florian T. Pokorny
Published in International Conference on Intelligent Robots and Systems (IROS 2019)
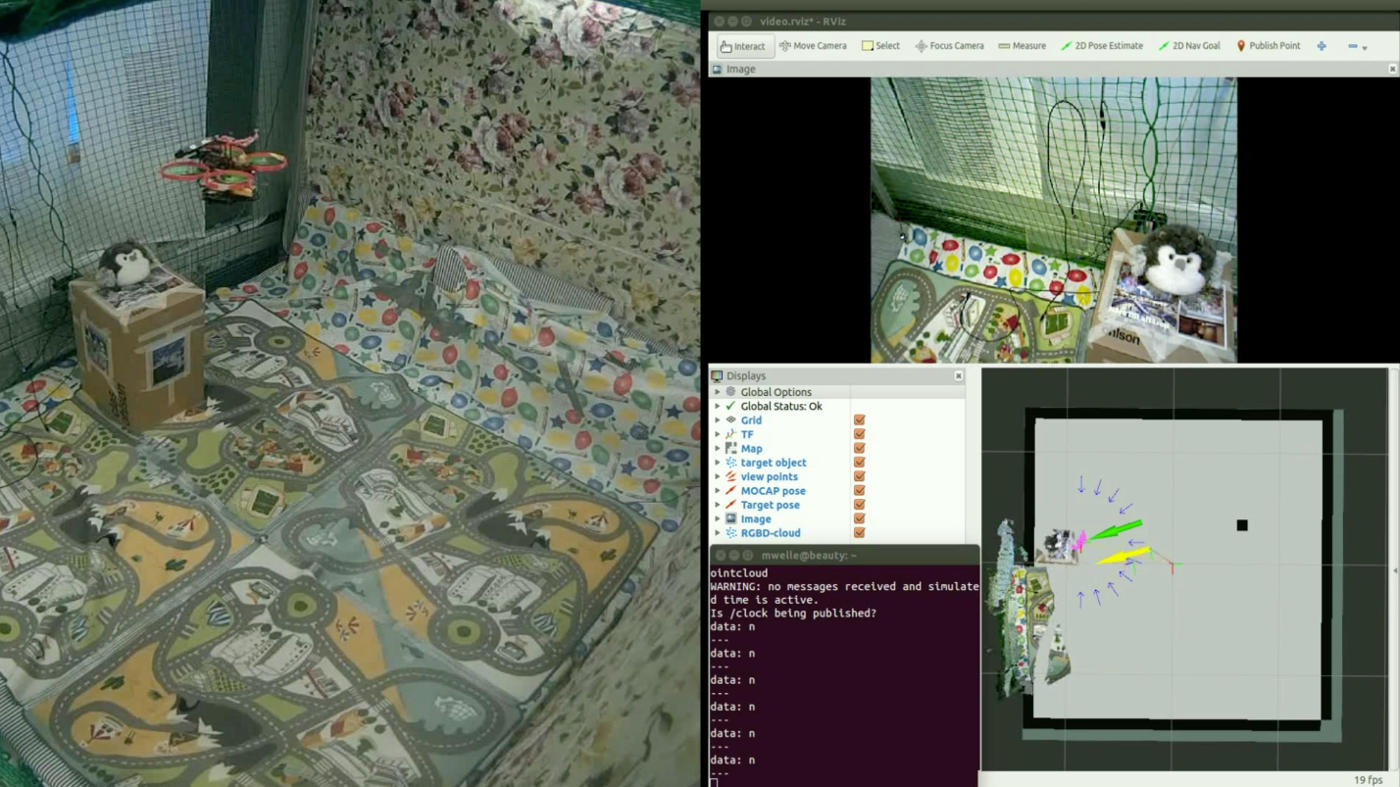
On the use of Unmanned Aerial Vehicles for Autonomous Object Modeling
In this paper we present an end to end object modeling pipeline for an unmanned aerial vehicle (UAV). We contribute a UAV system which is able to autonomously plan a path, navigate, acquire views of an object in the environment from which a model is built. The UAV does collision checking of the path and navigates only to those areas deemed safe. The data acquired is sent to a registration system which segments out the object of interest and fuses the data. We also show a qualitative comparison of our results with previous work.
4th Workshop on Representing and Manipulating Deformable Objects @ ICRA2024
Deformable objects (DOs) are ubiquitous in human environments. From food, clothes, cables, to body tissues, DOs are present in personal households, industrial environments, agricultural settings, and hospital rooms, to mention a few. Despite the ease humans can reliably manipulate them, they still pose a major challenge for robotics. Specifically, we identify the following open questions within the research community: i) How can we feasibly represent the state of a deformable object? ii) How do we accurately model and simulate its complex and non-linear dynamics? iii) Which hardware tools and platforms are most suitable for grasping and manipulating them? In continuation of the workshops held at ICRA in 2021, 2022, and 2023, we aim to once again gather the community in pursuit of answers to these and further questions on DOs. Our goal is to facilitate connections among scientists across diverse subfields of robotics, such as perception, simulation, control, and mechanics, spanning various stages of their careers and operating within different professional environments, including academia, industry, and research centers. Additionally, we aim to focus on the tangible advancements made in the field since the first workshop edition in 2021. We believe that this analysis will help identify promising directions and ultimately pave the way for practical, real-world solutions.
4th Workshop on Representing and Manipulating Deformable Objects @ ICRA2023
Michael C. Welle*, Martina Lippi*, Fangyi Zhang*, Lawrence Yunliang Chen*, Alberta Longhini, Danica Kragic, Daniel Seita*, David Held, Peter Corke
Workshop held at ICRA2024
Transferability in Robotics is a key step to achieving sufficient scale and robustness in order to make robots unambiguous in our everyday lives. The concept of transferability covers a wide range of topics such as i) Embodiment transfer - transferring from one robotic platform to another while considering their different embodiments, ii) Task/skill transfer - transferring methods or capabilities from one task to another, and iii) Knowledge transfer - transferring high-level concepts from one to another. These different areas also have different definitions of transferability and employ different approaches (e.g., representation learning, reinforcement learning, meta-learning, sim2real, interactive learning) for the respective task. While each of these fields has made headway in its own right, to really push forward the state of the art in transferability, a combination of contributions from the different fields is needed. The EU Horizon project euRobin aims to achieve transferability by not focusing on any specific sub-category but to share knowledge in a higher/more abstract way. The goal of this workshop is to combine the advances made in the individual fields into a more global picture by facilitating a common understanding of transferability, as well as highlighting contributions and encouraging collaborations between the different areas.
3nd Workshop on Representing and Manipulating Deformable Objects @ ICRA2023
Clothes, food, cables, and body tissue are just a few examples of deformable objects (DO) involved in both everyday and specialized tasks. Although humans are able to reliably manipulate them, automating this process using robotic platforms is still unsolved. Indeed, the high number of degrees of freedom involved in DOs undermines the effectiveness of traditional modelling, planning and control methods developed for rigid object manipulation. This paves the way for exciting questions from a research and application perspective. i) How to tractably represent the state of a deformable object? ii) How to model and simulate its highly complex and non-linear dynamics? iii) What hardware tools and platforms are best suited for grasping and manipulating? We aim to discuss these and more challenges that arise from handling deformable objects by connecting scientists from different subfields of robotics, including perception, simulation, control, and mechanics. Following the previous editions of the workshop at ICRA 2021 and ICRA 2022, the objective for the proposed third edition is to further identify promising research directions and analyze current state-of-the-art solutions with an emphasis on highlighting recent results since the 2022 workshop. We plan to facilitate this through invited talks and will foster new collaborations to connect young researchers with senior ones.
3nd Workshop on Representing and Manipulating Deformable Objects @ ICRA2023
Martina Lippi*, Daniel Seita*, Michael C. Welle*, Fangyi Zhang*, Hang Yin, Danica Kragic, Alessandro Marino, David Held, Peter Corke
Workshop held at ICRA2023
2nd Workshop on Representing and Manipulating Deformable Objects @ ICRA2022
Clothes, food, cables, and body tissue are just a few examples of deformable objects involved in both everyday and specialized tasks. Although humans are able to reliably manipulate them, automating this process using robotic platforms remains challenging. Indeed, the high number of degrees of freedom involved undermines the effectiveness of traditional modelling, planning and control methods developed for rigid object manipulation. This paves the way for exciting questions from a research and application perspective. i) How to tractably represent the state of a deformable object? ii) How to model and simulate its highly complex and non-linear dynamics? iii) What hardware tools and platforms are best suited for grasping and manipulating? We aim to discuss these and more challenges that arise from handling deformable objects by connecting scientists from different subfields of robotics, including perception, simulation, control, and mechanics.
Representing and Manipulating Deformable Objects Workshop @ ICRA2021
Deformable objects manipulation is a key component of a variety of everyday and specialized applications, ranging from domestic housework such as cloth folding or food handing, to medical scenarios such as surgery and suturing, up to industrial setups such as cable insertion. However, the large configuration space of deformable objects causes traditional modelling, planning and control approaches to fail when dealing with them. More specifically, unlike in the case of rigid objects, two main challenges arise: i) there is no clear and unified state representation and ii) the dynamics is complex and highly non-linear. This leads to the absence of current unified solutions and to highly domain-specific approaches emerging in the fields of perception, simulation, control and mechanics. In addition, the lack of scalable simulation environments limits possible developments in the above fields. We believe that robust progress can only be achieved by combining these complementary areas of robotics. Therefore, this workshop aims to start a discussion about the current state-of-the-art and possible research directions as well as connect people from different sub-fields to solve deformable objects challenges.
Representing and Manipulating Deformable Objects Workshop @ ICRA2021
Martina Lippi*, Michael C. Welle*, Anastasiia Varava*, Hang Yin, Rika Antonova, Florian T. Pokorny, Danica Kragic, Yiannis Karayiannidis,
Ville Kyrki, Alessandro Marino, Julia Borras, Guillem Alenya, Carme Torras
Workshop held at ICRA2021
Quest2ROS: An App to Facilitate Teleoperating Robots
Teleoperation is an integral part of robotics research. In this work, we present Quest2ROS, a stand-alone app available %Metas AppLab for Oculus Quest 2 and 3 that facilitates the teleoperation of robots via ROS. Quest2ROS publishes the position and velocity of both hand-held controllers, the button pressed as well as enables haptic feedback via the controller vibration. The Quest headset does not have to be worn at teleoperation time to not restrict the operator, furthermore, a simple way to align the coordinate frame of the controller with any given robot in the real world is provided. We measure the tracking accuracy of a Quest 2 to be 0.46 mm on average, with mean latency between the Quest 2 and a ROS node being 82 ms and update frequency of relevant ROS topics being 71.96 Hz.
Quest2ROS: An App to Facilitate Teleoperating Robots
Michael C. Welle*, Nils Ingelhag*, Martina Lippi, Maciej Wozniak, Andrea Gasparri, Danica Kragic
7th International Workshop on Virtual, Augmented, and Mixed-Reality for Human-Robot Interactions
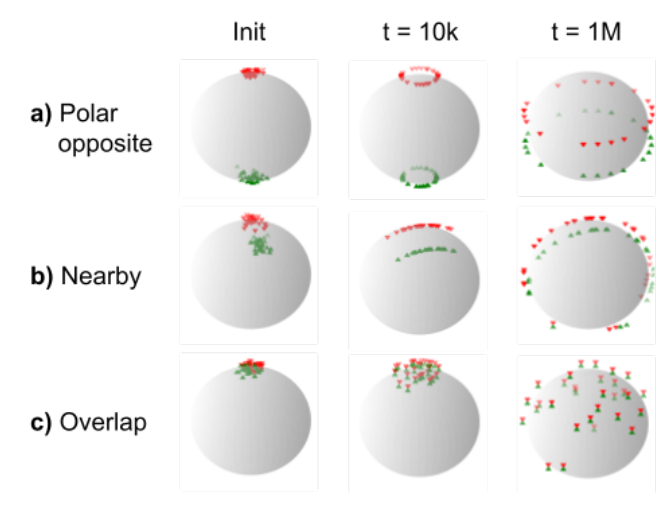
This work examines the phenomenon of the modality gap observed in CLIP-based multimodal learning methods. The modality gap in this context refers to the separation of image and text embeddings in the joint latent space. Some previous research has attributed the gap to cone effect of neural network initialization and suggested closing may not be necessary. However, this study argues that the modality gap is associated with local minima in the CLIP loss function. Through a series of proof-of-concept experiments, we illustrate these local minima and the difficulty of avoiding them in practice. Overall, this work hopes to provide better insight into the root cause of the modality gap.
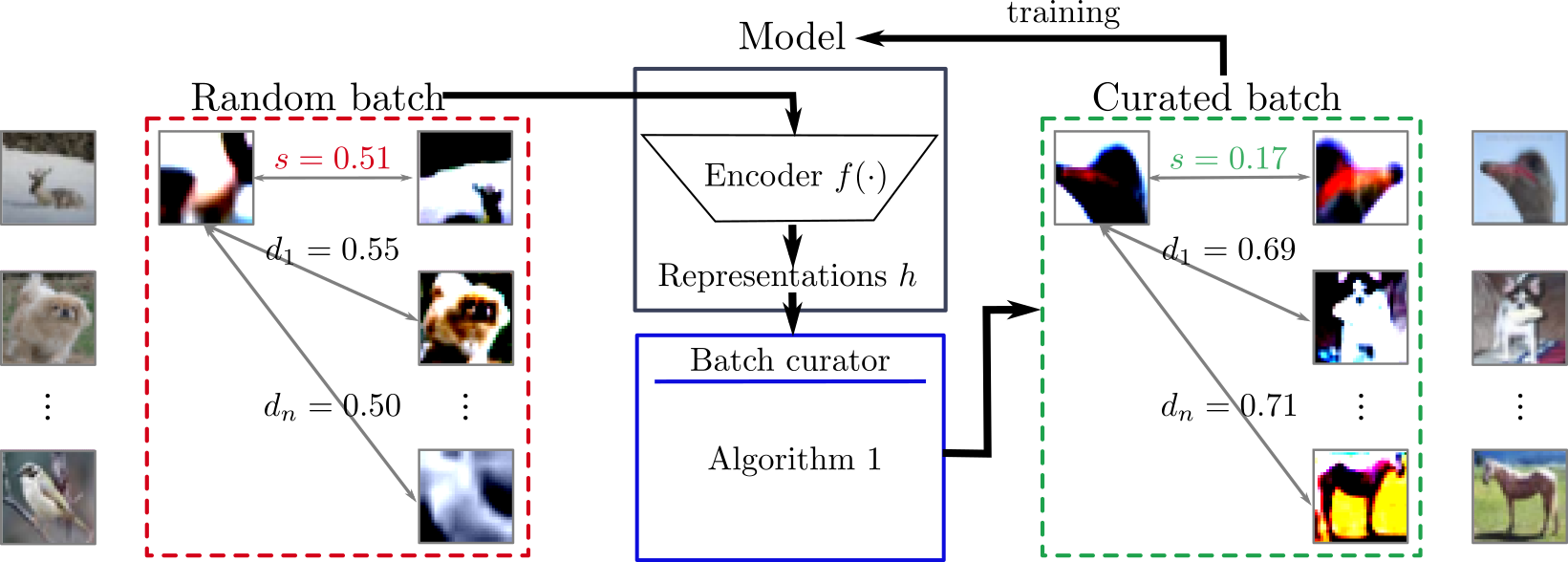
Batch Curation for Unsupervised Contrastive Representation Learning
The state-of-the-art unsupervised contrastive visual representation learning methods that have emerged recently (SimCLR, MoCo, SwAV) all make use of data augmentations in order to construct a pretext task of instant discrimination consisting of similar and dissimilar pairs of images.
Similar pairs are constructed by randomly extracting patches from the same image and applying several other transformations such as color jittering or blurring, while transformed patches from different image instances in a given batch are regarded as dissimilar pairs. We argue that this approach can result
similar pairs that are \textit{semantically} dissimilar.
In this work, we address this problem by introducing a \textit{batch curation} scheme that selects batches during the training process that are more inline with the underlying contrastive objective. We provide insights into what constitutes beneficial similar and dissimilar pairs
as well as validate \textit{batch curation} on CIFAR10 by integrating it in the SimCLR model.
Batch Curation for Unsupervised Contrastive Representation Learning
Michael C. Welle*, Petra Poklukar*, and Danica Kragic
Workshop on Self-Supervised Learning for Reasoning and Perception, Workshop at International Conference on Machine Learning 2021
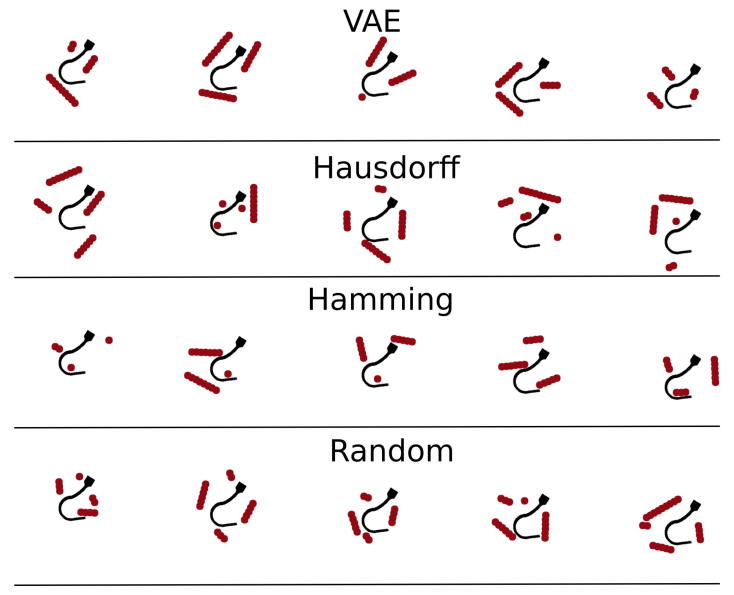
State Representations in Robotics: Identifying Relevant Factors of Variation using Weak Supervision
Representation learning allows planning actions directly from raw observations. Variational Autoencoders (VAEs) and their modifications are often used to learn latent state representations from high-dimensional observations such as images of the scene. This approach uses the similarity between observations in the space of images as a proxy for estimating similarity between the underlying states of the system. We argue that, despite some successful implementations, this approach is not applicable in the general case where observations contain task-irrelevant factors of variation. We compare different methods to learn latent representations for a box stacking task and show that models with weak supervision such as Siamese networks with a simple contrastive loss produce more useful representations than traditionally used autoencoders for the final downstream manipulation task.
State Representations in Robotics: Identifying Relevant Factors of Variation using Weak Supervision
Constantinos Chamzas*, Martina Lippi*, Michael C. Welle*, Anastasiia Varava, Lydia Kavraki, and Alessandro Marino, and Danica Kragic
NeurIPS 2020 Workshop on Robot Learning
We present a framework for visual action planning of complex manipulation tasks with high-dimensional state spaces such as manipulation of deformable objects. Planning is performed in a low-dimensional latent state space that embeds images. We define and implement a Latent Space Roadmap (LSR) which is a graph-based structure that globally captures the latent system dynamics. Our framework consists of two main components: a Visual Foresight Module (VFM) that generates a visual plan as a sequence of images, and an Action Proposal Network (APN) that predicts the actions between them. We show the effectiveness of the method on a simulated box stacking task as well as a T-shirt folding task performed with a real robot.
Martina Lippi*, Petra Poklukar*, Michael C. Welle*, Anastasiia Varava, Hang Yin, Alessandro Marino, and Danica Kragic
RSS 2020 Workshop - Visual Learning and Reasoning for Robotic Manipulation
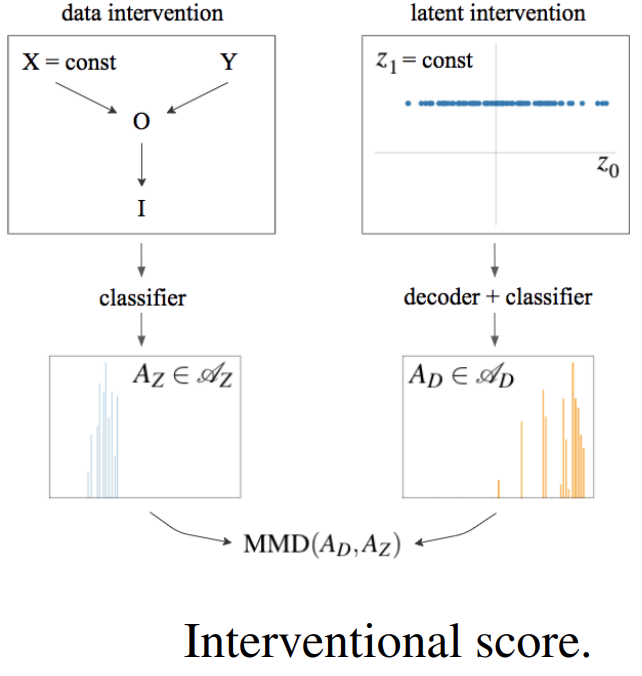
Learning efficient and compact representations is crucial for various problems in artificial intelligence. Designing evaluation procedures that are independent from the task at hand is one of the key challenges of this area of research. Inspired by the theory of causal reasoning, we consider interventions for analysing data representation. Specifically, we leverage them to introduce Interventional Score for measuring disentanglement of the latent representations.


 Incorporating formal methods into reinforcement learning (RL) has the potential to result in the best of both worlds, combining the robustness of formal guarantees with the adaptability and learning capabilities of RL, though careful design is needed to balance safety and exploration.
In his work, we propose a framework to mitigate this loss of exploration while still allowing for the safety of the system to be ensured. Specifically, we introduce a less restrictive method that can reduce the conservativeness of formal methods by refining a disturbance model using online collected data and it evaluates the safety of a learning-based controller, using computationally efficient zonotopic reachability analysis for the safety analysis to facilitate a real-time implementation. We validate the framework in a real-world drone flight through a canyon, where the drone is subjected to unknown external disturbances and the framework is tasked with learning those disturbances online and adjusting the safety guarantees accordingly. The results show that the framework enables a less restrictive online training of learning-based controllers without compromising the safety of the system.
Incorporating formal methods into reinforcement learning (RL) has the potential to result in the best of both worlds, combining the robustness of formal guarantees with the adaptability and learning capabilities of RL, though careful design is needed to balance safety and exploration.
In his work, we propose a framework to mitigate this loss of exploration while still allowing for the safety of the system to be ensured. Specifically, we introduce a less restrictive method that can reduce the conservativeness of formal methods by refining a disturbance model using online collected data and it evaluates the safety of a learning-based controller, using computationally efficient zonotopic reachability analysis for the safety analysis to facilitate a real-time implementation. We validate the framework in a real-world drone flight through a canyon, where the drone is subjected to unknown external disturbances and the framework is tasked with learning those disturbances online and adjusting the safety guarantees accordingly. The results show that the framework enables a less restrictive online training of learning-based controllers without compromising the safety of the system.